Software is not a building. It is a living organism. Buildings get renovated; organisms must continuously metabolize or die.
In Part 1, I argued that maintaining a personal distro is now feasible for a single person with AI assistance. That was the “Why.”
This is the “How.” And the “How” has a name: Carried Patch Queue, or CPQ.
But before we get to the good stuff, let’s talk about the methods that will eventually kill your project.
The Anatomy of Traditional Downstreams (The Old Ways)
There are three classical approaches to maintaining a downstream, and they all share the same fatal flaw: they manage files about code instead of managing code directly.
1. Directory Hijacking / Override
This is the Brave model. You take Chromium’s source, and you maintain a parallel directory structure that shadows upstream files. Your build system is wired to prefer your versions over theirs.
Brave’s chromium_src_override directory is the canonical example. It works — for a company with dozens of engineers and a CI budget the size of a small country’s GDP. For an individual? You are now an unpaid archaeologist. Every upstream file move, every refactor, every renamed directory silently breaks your overrides. You don’t get merge conflicts; you get silent wrongness. That’s worse.
2. Patch File Management / Quilt
This is the Debian way. You maintain a series of .patch files in a debian/patches/ directory, applied in order via quilt or dpkg-source. Each patch is a diff. The series file is an ordered list.
Debian’s packaging policy has been refined over decades, and it works for an institution with hundreds of package maintainers. But patches are inert text files. They don’t participate in git’s merge machinery. They can’t be rebased. They can’t be cherry-picked. When upstream moves, you regenerate diffs by hand (or by script, which is just hand with extra steps). You’re a patch janitor maintaining a museum of diffs.
3. Hook / Compile-time Wrappers
This is the Nginx model. Upstream provides a module system, and you bolt on functionality at compile time or via dynamic loading. Your downstream is expressed as build flags and module directories.
This works until it doesn’t. The moment you need to change core behavior — not extend it, but change it — you’re back to maintaining patches anyway, except now they’re hidden inside a build system nobody wants to debug.
The Common Disease
All three methods create what I call Software Archaeology Debt. You’re not maintaining a living branch of code. You’re maintaining a description of how code should be different. The map is not the territory, and when the territory shifts, your map is wrong in ways that are expensive to discover.
These approaches made sense when git didn’t exist, or when your downstream was so large that branch-based workflows couldn’t scale. But for a personal distro with 5–20 patches? They’re bringing a siege engine to a knife fight.
The CPQ Holy Trinity: The Masters of the Branch
Now let’s look at the projects that got it right. Three industrial-scale upstream/downstream pairs that use pure branch rebase — what I’m calling Carried Patch Queue (CPQ) — and have battle-tested it at scale.
1. GrapheneOS on AOSP: The Rebase Purists
GrapheneOS maintains a hardened Android distribution on top of AOSP. Their approach is religious in its purity: zero merge commits, perfectly linear history.
Every time Google cuts a new AOSP tag, the GrapheneOS team rebases their entire patch stack on top of it. Their repository structure is a constellation of repos, each carrying a linear sequence of commits on top of the corresponding AOSP repo.
The key insight from GrapheneOS: a rebase is a statement of intent. Every commit in their history says “this change is still needed, and I have verified it applies cleanly to the current upstream.” A merge commit says nothing of the sort. A merge commit says “I pressed a button and git didn’t complain.”
Daniel Micay’s development documentation makes this philosophy explicit: you rebase, you verify, you carry forward. No merge bubbles. No octopus merges. No “fix merge conflict” commits that nobody will ever read.
2. CentOS Stream on Fedora/RHEL: The Topic Stack Janitors
CentOS Stream is Red Hat’s public development branch for what becomes RHEL. Their relationship with upstream projects like systemd is instructive.
Red Hat’s engineers contribute heavily to systemd upstream, but RHEL ships a snapshot that carries backported patches and enterprise-specific fixes. Each patch is an atomic commit with rich metadata: Bugzilla links, CVE references, upstream commit hashes, and justification for why it’s carried.
The lesson from CentOS Stream: every carried patch must justify its existence. Their contribution guidelines require that patches include upstream status (merged, proposed, or permanent deviation) and a rationale. This is not bureaucracy; this is survival. When you carry 200 patches, you need metadata or you drown. When you carry 10, the habit still saves you — because the day you can’t remember why patch #7 exists is the day you’re afraid to drop it, and fear of dropping patches is how downstreams get fat.
3. OpenShift on Kubernetes: The Industrial Rebase
OpenShift is Red Hat’s enterprise Kubernetes distribution. Their relationship with upstream Kubernetes is the most heavily automated CPQ operation I know of.
OpenShift maintains carry patches as a linear sequence of commits on top of each Kubernetes release. They use what I call shadow syncing: automated CI that continuously attempts to rebase their patch stack onto upstream HEAD, catching conflicts early rather than discovering them at release time.
Their REBASE.openshift.md documents the exact rebase process. It’s not glamorous. It’s engineering discipline applied to the problem of “how do we carry 100+ patches across quarterly Kubernetes releases without losing our minds?”
The OpenShift lesson: automate the rebase attempt, not the rebase decision. Their bots try the rebase continuously. When it fails, a human investigates. The human brings judgment; the bot brings relentlessness.
What They All Share
These three projects don’t manage files about code. They manage a linear sequence of code changes. Each commit is a first-class citizen in git’s DAG. Each commit can be rebased, cherry-picked, bisected, reverted, or dropped. Each commit participates in the full power of git’s merge machinery.
That is the fundamental advantage of CPQ over every alternative.
Why CPQ is the Personal Distro Sweet Spot
“But wait,” you say. “Those are institutional projects with paid engineers. How does this apply to me, one person, maintaining my downstream of [some CLI tool]?”
It applies better to you. Here’s why.
The Small Delta Advantage
GrapheneOS carries hundreds of patches across dozens of repos. OpenShift carries 100+ patches on a codebase with millions of lines. CentOS Stream manages patches across thousands of packages.
Your personal distro carries 5–20 patches.
A linear rebase of 5–20 commits is trivial. It’s a “Pearl Necklace” — a short, beautiful strand where each pearl is a self-contained change. When upstream moves, you run git rebase and most of the time it just works. When it doesn’t, you have a small, well-understood conflict to resolve.
The methods that institutions invented to manage hundreds of patches (quilt, directory overrides, build-system wrappers) are solutions to a scale problem you don’t have. CPQ gives you the same semantic richness — every patch is a commit, every commit tells a story — without the overhead.
The AI Multiplier
This is the 2026 superpower.
In 2020, a rebase conflict meant you, staring at <<<<<<< HEAD markers, trying to remember what your patch was supposed to do and what upstream changed and why.
In 2026, you paste the conflict into an LLM and say “here’s my carried patch, here’s what upstream changed, resolve this conflict preserving my intent.” And it does. Correctly, most of the time. And when it’s wrong, it’s wrong in ways that are easy to spot because the patch is atomic and small.
AI is the perfect “Patch Janitor.” It doesn’t get bored. It doesn’t forget context. It can read the upstream commit message, read your patch’s commit message, understand both intents, and produce a resolution. This is exactly the kind of structured, context-rich, low-creativity work that LLMs excel at.
CPQ + AI means a single person can maintain a downstream with the same rigor that Red Hat applies to RHEL. The AI handles the mechanical rebasing; the human handles the judgment calls: “should I still carry this patch? Should I upstream it? Should I drop it?”
Best Practices for Personal CPQ
If you’re going to do this, do it right:
-
Linear history or death. No merge commits in your patch stack. Ever.
git rebase, notgit merge. If your history isn’t linear, you can’t reason about your patches as an ordered sequence, and the whole model collapses. -
Atomic commits. Each carried patch does one thing. One bug fix. One default change. One feature addition. If you can’t describe the patch in one sentence, split it. This is why OpenShift requires atomicity in their carry patches — it’s not pedantry, it’s survival.
-
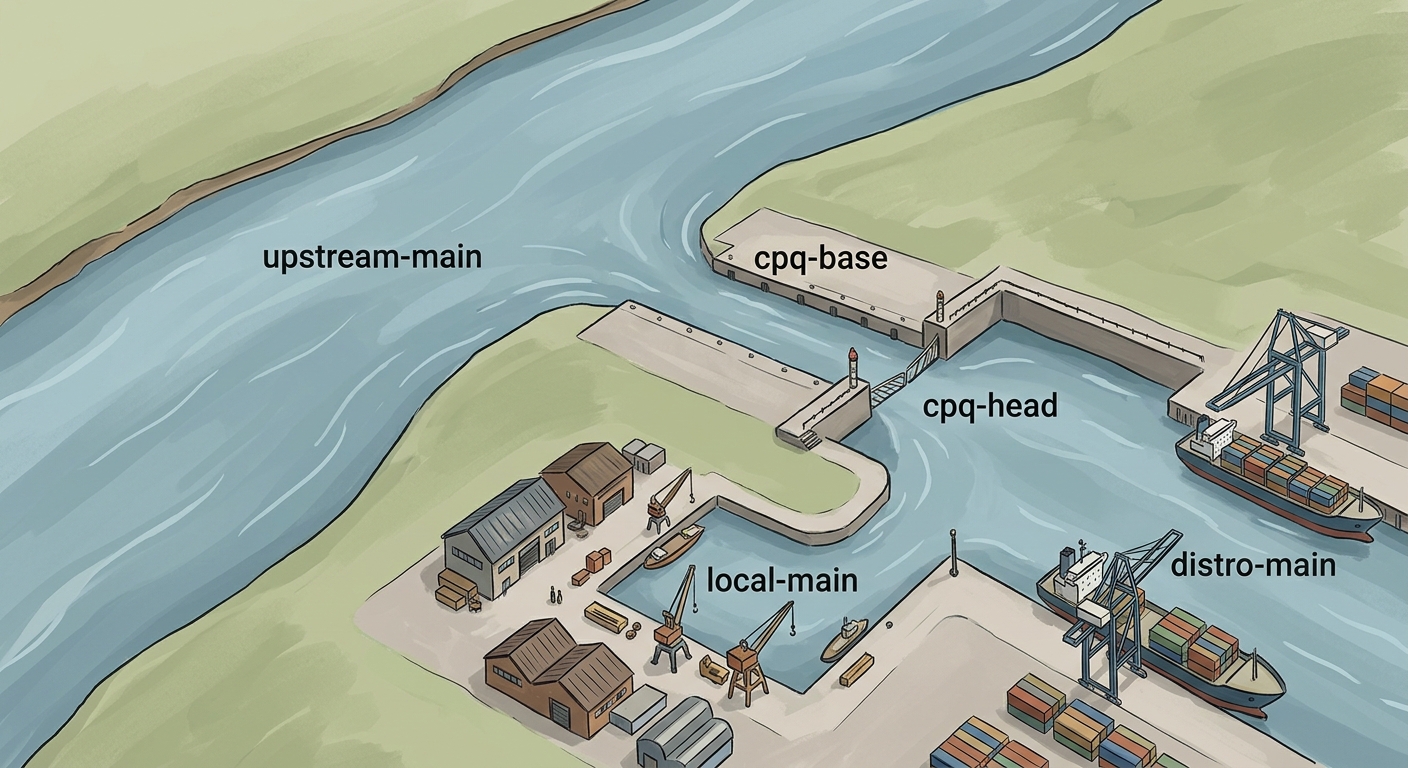
Use explicit CPQ names, not vibes. Your downstream should have a named
upstream-main, a namedlocal-main, and a nameddistro-main. More importantly, your carried stack should have a namedcpq-baseand a namedcpq-head.cpq-baseis the upstream anchor you are rebasing onto.cpq-headis a pointer to the top of the current carried stack.
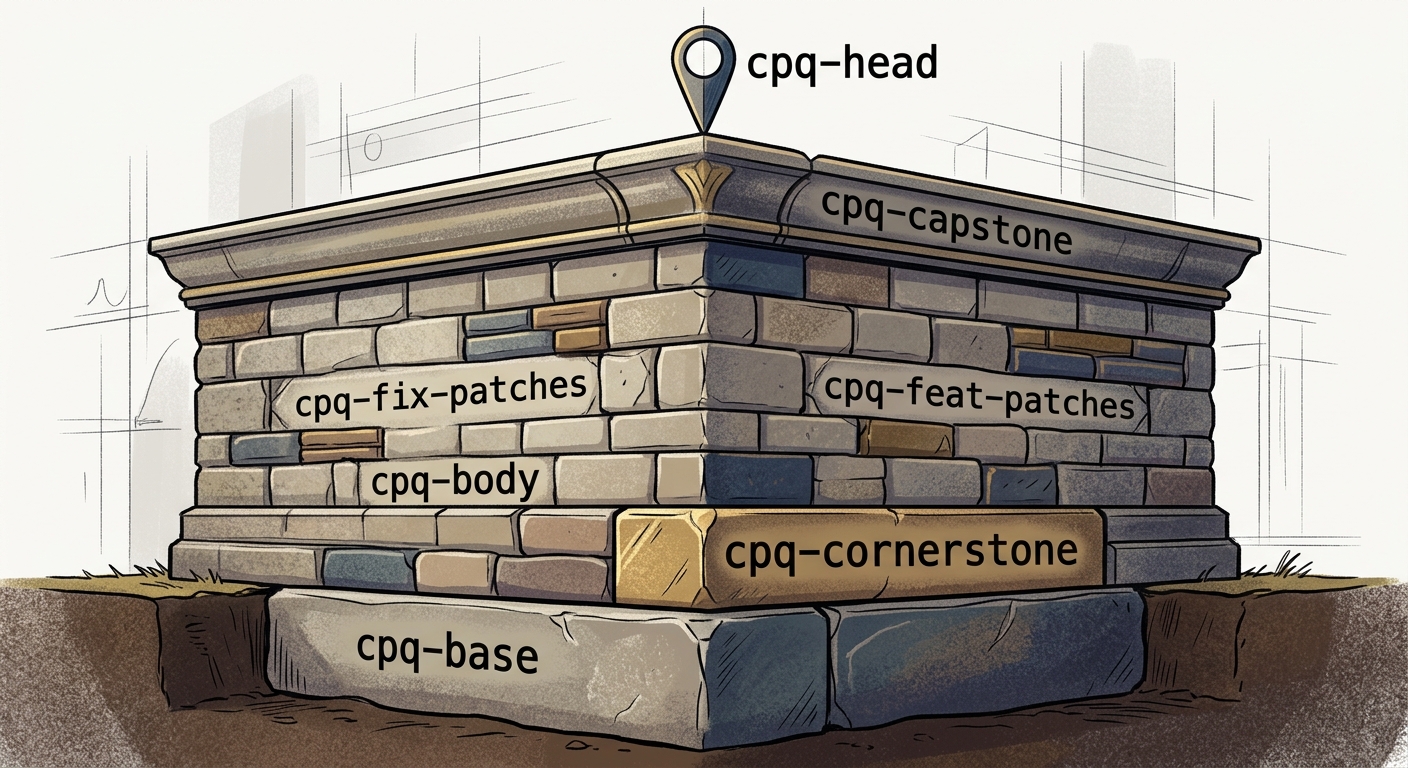
- Structure the stack. In a healthy personal distro, the stack is not just a blob of commits. It has layers:
cpq-cornerstone, thencpq-body, thencpq-capstone. The cornerstone is your downstream identity — policy, branding, and foundational local rules. The body is the main carried patch set:cpq-fix-patchesfirst (test fixes before functional fixes), thencpq-feat-patches. The capstone is a regenerated metadata and release-state snapshot commit. In finalized state,cpq-headpoints tocpq-capstone.
-
Shadow Sync. Set up CI (GitHub Actions, a cron job, whatever) that periodically attempts to move from the current
cpq-baseto a newer upstream tag or commit and replay the carried stack. If it succeeds, you’re green. If it fails, you get an early warning instead of a surprise at the worst possible time. -
Patch ledger in commit messages and metadata. Each carried commit’s message should note: upstream status (merged/proposed/permanent), why it’s carried, and drop condition (e.g., “drop when upstream ships v3.2”). Then your capstone metadata should record the current patch-to-commit mapping after each rebase. This is your memory. Without it, you’ll be afraid to drop patches, and fear of dropping patches is how downstreams get fat and stupid.
-
Upstream aggressively. Every patch you carry is a liability. File PRs upstream. If they merge, drop the carry. The best patch queue is a short one.
The Experiment
I’m putting my money where my mouth is.
I’m applying this CPQ model to my own projects right now:
-
OpenClaw: A downstream of an open-source CLI tool where I carry patches for my own workflow defaults and bug fixes that upstream hasn’t merged yet. Each fix lives on its own topic branch, filed as a separate PR upstream.
local-mainis my local realization ofcpq-head. -
Hermes: My personal downstream of a messaging tool, carrying patches for notification defaults, UI tweaks, and integration hooks that are too opinionated for upstream.
Both use an explicit CPQ model: a named cpq-base, a structured carried stack, and a cpq-head that points at the finalized state. Both rebase on every upstream release. Both have shadow sync CI that tells me when upstream has moved. And both are maintained by one person — me — with an AI agent handling the mechanical rebasing.
It’s early. I’ll report back.
But I can already tell you this: the maintenance burden feels qualitatively different from every fork I’ve ever maintained. Instead of the slow dread of “I should update from upstream but I’m scared,” there’s a routine: upstream tags, I rebase, the AI resolves the trivial conflicts, I review the non-trivial ones, and my pearl necklace stays clean.
The Punchline
The old ways of managing downstreams — directory overrides, patch files, build-time hooks — were invented for a world where git didn’t exist or where patch counts were in the hundreds.
You are not Brave. You are not Debian. You are not Nginx.
You are one person with 5–20 patches and an AI that can rebase.
Use CPQ. Keep your history linear. Keep your patches atomic. Automate the rebase attempt. Apply human judgment to the rebase decision.
That’s the engineering of the downstream.
That’s how you maintain your personal distro.